Sentiment analysis on tweets using a streaming architecture
The requirements for the project are to build an infrastructure capable of handling streaming data, using the Lambda architecture1 as a reference, and using open source technologies.
The project mainly consists of two parts:
- Developing tools and procedures to run a "general-purpose" Big Data architecture capable of handling both streaming and batch workload, with the possibility of running on clusters.
- Developing a use case to deploy on such architecture. The chosen one is sentiment analysis over time for a particular word on Twitter (so focus on the streaming part) while still ingesting the data to a data lake, and having the possibility of scheduling batch jobs on it.
This document is a reference for both parts (see next two chapters).
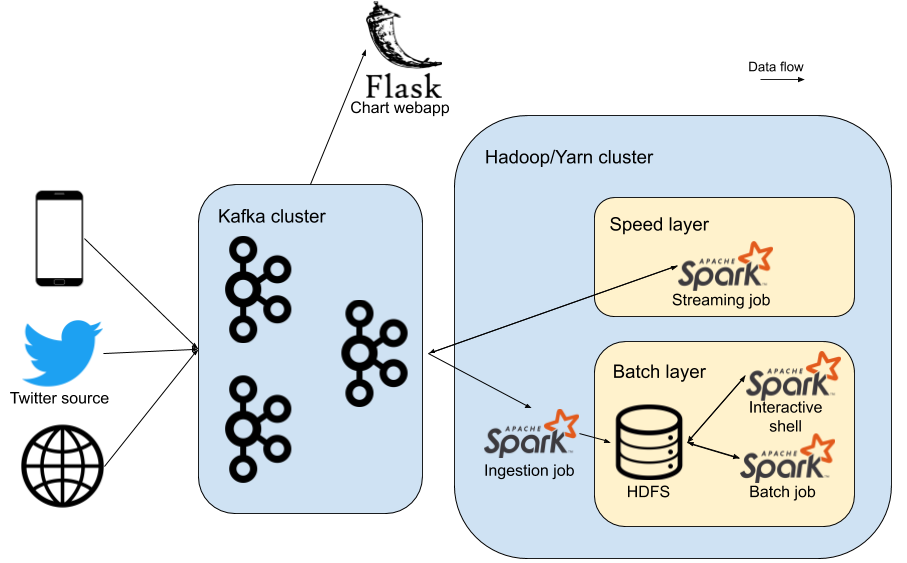
Technologies and components
Before diving into the practical part, here is a very brief summary of the technologies and components used in the project and their role in it.
General architecture
Docker
Docker is a popular platform for virtualization using "containers". It's very handy for deploying software efficiently on any machine that supports it. It also offers some orchestration features with Docker Swarm. In the project all essential parts of the architecture and the demo have been "containerized".
Kafka/Zookeeper
Apache Kafka is a streaming data platform, fault-tolerant, easy to use, and capable of handling big quantities of data through horizontal scaling.
Yarn/Hadoop
Hadoop was born around the Map/Reduce framework, but nowadays it's a vast ecosystem. The role of the Hadoop cluster in this project is to have an executing platform for Spark (through Yarn) and also having a distributed file system to use as a data lake (HDFS).
Spark
Spark is an in-memory general processing engine. It has an eminent role in the Hadoop ecosystem, offering numerous advantages over the vanilla Map/Reduce framework. It started with a not so high-level API (RDD), but now it's moving toward the direction of a Dataset/Dataframe API (similar to Pandas ones).
It offers extensions for specific applications (e.g. Machine Learning). For the demo the main interest is in the Structured Streaming part of Spark. Spark is a core part of this architecture, allowing to process streaming data ingested from Kafka (serving results to another Kafka topic), to persist such data to HDFS, and to run other jobs.
Demo components
Twitter producer (Tweepy + Kafka Python API)
Here Tweepy is used, for its simplicity. The script registers for a stream of tweets related to a particular word, and these are sent to a Kafka topic (through kafka-python module). Twitter developer credentials are needed to make the API work (need to sign up).
Dashboard (Flask + ChartJS)
A small dashboard prototype to show a graphical representation of the results of the streaming process. Technologies used are Flask (a Python module to build web applications) and ChartJS (an easy Javascript library to make charts).
-
https://en.wikipedia.org/wiki/Lambda_architecture ↩